
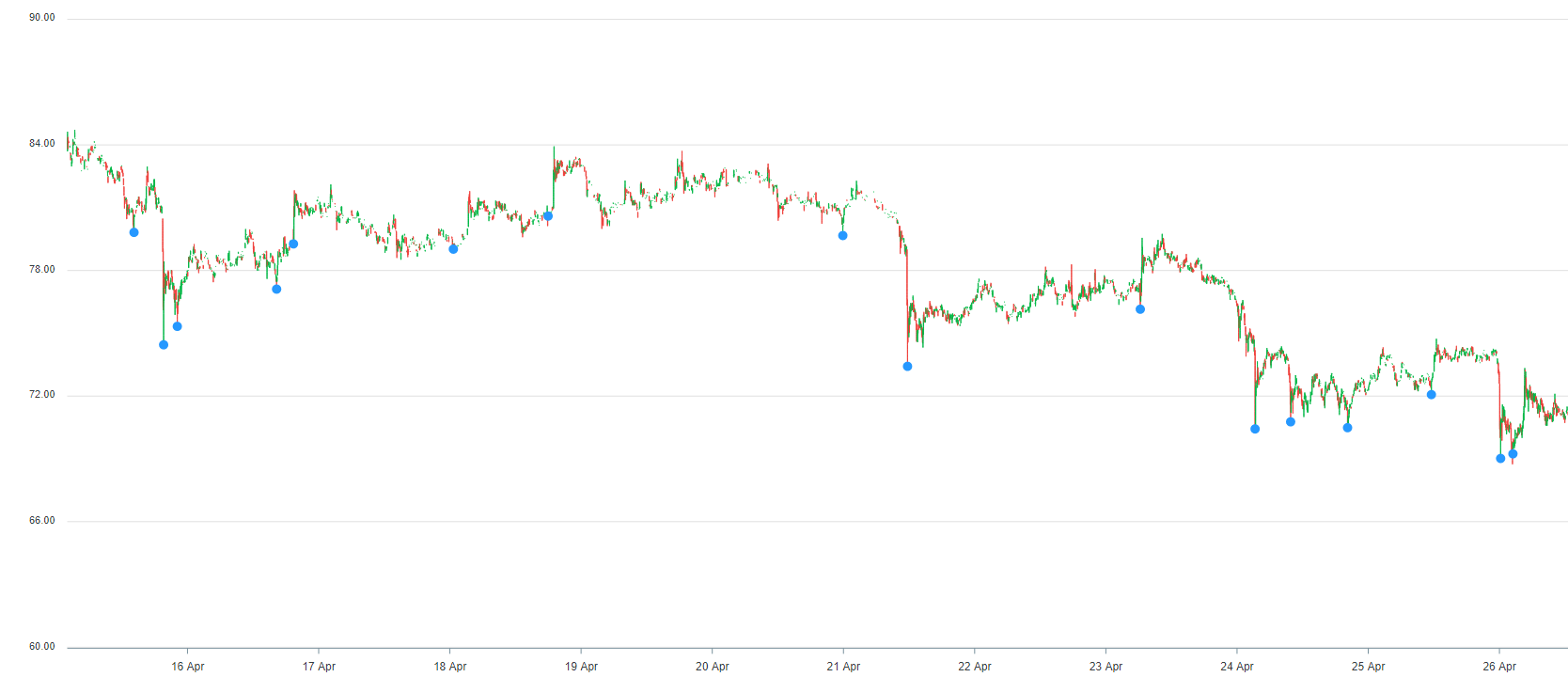
我正在设计一个算法,它将计算烛台图中存在强大支持区域的区域。在这种情况下,“支撑区域”是指图表中股票价格在短时间内大幅上涨的区域。(请参见下图,蓝点代表这些强大的支持区域)
我处理的数据是一个超过6000个TOHLC(时间戳、开盘价、高价、低价、收盘价)值的列表。例如,此数据列表中的第一个条目是:
[1555286400, 83.7, 84.63, 83.7, 84.27]
我构建算法的方式如下:
1.)6000个TOHLC值的列表被分成30个TOHLC值的子列表(30是我任意选择的数字)。然后从这些子列表中获得最低低价(LLP)。使用这种方法的目的是在图表中找到价格下跌的区域。
2.)下一步是确定价格从这些低点上涨了多高。为此,我从低点取下30个烛台值,并确定最高价格(HHP)是多少。那么,如果HHP/LLP
上图中的蓝色圆点表示算法可接受的支持区域。就我正在努力实现的目标而言,它似乎运行良好。
所以我的问题是:是否有人可以对这个算法提出任何改进建议,或者指出其中的任何错误?
谢谢
我可能理解错了,但是,从你的解释来看,你似乎是在单独的30个ish子列表中进行计算,然后将它们组合在一起。
那么,如果LLP是子列表N的第30个元素,HHP是子列表n1的第一个元素呢?如果你考虑到了这一点,那没关系。
>
如果你没有考虑到这一点,我建议你在阅读这些数据时采用移动窗口的方法。因此,您可以从6000到HLC的第0个元素开始,从30大小的窗口开始,将其按1:1滑动。这样,您就不会错过任何值。
一些选定的蓝点比其他蓝点具有更高的倾角。为什么呢?我会把它们分成另一个分类器。如果要将它们存储到对象中,请同时存储倾斜率。
金融业不建议使用浮点数。如果可能的话,我会使用一种不同的方法,也许是分类器,只使用整数。到目前为止,它可能不会困扰您或您的项目,但可以肯定的是,当这些数字在未来累积起来时,它将开始产生错误的结果。
