这是我的密码:
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn import preprocessing
import os
import subprocess
def categorical_split():
colors = ['blue', 'green', 'yellow', 'green', 'red']
sizes = ['small', 'large', 'medium', 'large', 'small']
size_encoder = preprocessing.LabelEncoder()
sizes = size_encoder.fit_transform(sizes).reshape(-1, 1)
color_encoder = preprocessing.LabelEncoder()
colors = size_encoder.fit_transform(colors).reshape(-1, 1)
dt = DecisionTreeClassifier( random_state=99)
dt.fit(colors, sizes)
with open("dt.dot", 'w') as f:
export_graphviz(dt, out_file=f,
feature_names='colors')
command = ["dot", "-Tpng", "dt.dot", "-o", "dt.png"]
subprocess.check_call(command)
categorical_split()
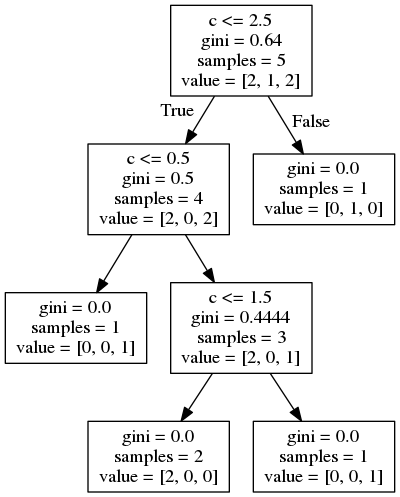
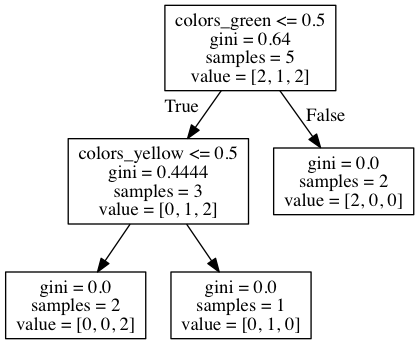
由于Scikit学习中的决策树不能直接处理分类变量,我不得不使用LabelEncoder。在图中,我们看到像c这样的分裂
这实际上是一种非常有效的方法,不应该对模型性能有害。但这确实使模型有点难以阅读。一个很好的方法是使用pd。获取虚拟对象,因为这将为您处理模型名称:
import pandas as pd
df = pd.DataFrame({'colors':colors})
df_encoded = pd.get_dummies(df)
dt.fit(df_encoded, sizes)
with open("dt.dot", 'w') as f:
export_graphviz(dt, out_file=f,
feature_names=df_encoded.columns)
command = ["dot", "-Tpng", "dt.dot", "-o", "dt.png"]
subprocess.check_call(command)