我想在下面的图中填写蓝色的“位置”部分。数据本身标志着重大位置变化的发生,是15分钟样本的时间序列,并重复上一个位置,直到发生新的位置变化事件。例如,一旦注册了“home”,它的列就保持为1,其他所有列都保持为0。接下来访问“工作”时,该列变为1,home在0处加入其他列。

u1 = userLocAppDfs['user_3'].copy()
# https://stackoverflow.com/questions/11927715/how-to-give-a-pandas-matplotlib-bar-graph-custom-colors
locations = [(x/8.75, x/40.0, 0.85) for x in range(5)] # color grad
u1[[' bar', ' grocers', ' home', ' lunch', ' work']].plot(color=locations, figsize=(15,10))
u1[' app_3'].plot(color='orange')
u1[' app_1'].plot(color='r')
我注意到fillstyle='full'没有做任何事情。填充图形区域的正确方法是什么?
app_1 app_2 user bar grocers home lunch park relatives work
date
2017-08-29 14:00:00 0.013953 0.052472 user_1 0.0 0.0 0.0 0.0 0.0 0.0 1.0
2017-08-29 14:15:00 0.014070 0.052809 user_1 0.0 0.0 0.0 0.0 0.0 0.0 1.0
2017-08-29 14:30:00 0.014186 0.053146 user_1 0.0 0.0 1.0 0.0 0.0 0.0 0.0
2017-08-29 14:45:00 0.014302 0.053483 user_1 0.0 0.0 1.0 0.0 0.0 0.0 0.0
2017-08-29 15:00:00 0.014419 0.053820 user_1 0.0 0.0 1.0 0.0 0.0 0.0 0.0
我认为不可能直接从数据帧使用pandas绘图,但可以从matplotlib使用fill_between。您需要在数据帧的每一列上执行此操作(“条”、“家”、“工作”等)。可以手动创建轴,并告诉matplotlib和pandas打印到该轴上
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1,1)
for location in [' bar', 'grocers', ' home']: # or whatever subset of columns you want
ax.fill_between(range(len(u1[location]), u1[location], step='post')
u1[' app_3'].plot(ax=ax, color='orange')
# etc..
另外,fillstyle参数用于为每个数据点设置标记,并希望修改其外观时:https://matplotlib.org/gallery/lines_bars_and_markers/marker_fillstyle_reference.html
编辑:使用您提供的数据更新示例。我修改了数据,在工作和家庭之间的酒吧增加了一个停靠点,以给出一个看起来更好的情节。
import matplotlib.pyplot as plt
import pandas as pd
columns = ['date', 'app_1', 'app_2', 'user', 'bar', 'grocers', 'home', 'lunch', 'park', 'relatives', 'work']
data = [['2017-08-29 14:00:00', 0.013953, 0.052472, 'user_1', 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0], ['2017-08-29 14:15:00', 0.014070, 0.052809, 'user_1', 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0], ['2017-08-29 14:30:00', 0.014186, 0.053146, 'user_1', 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0], ['2017-08-29 14:45:00', 0.014302, 0.053483, 'user_1', 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0], ['2017-08-29 15:00:00', 0.014419, 0.053820, 'user_1', 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0]]
df = pd.DataFrame(data, columns=columns)
height = df[['app_1', 'app_2']].max().max()
fig, ax = plt.subplots(1,1)
df['app_1'].plot(ax=ax, color='orange')
df['app_2'].plot(ax=ax, color='purple')
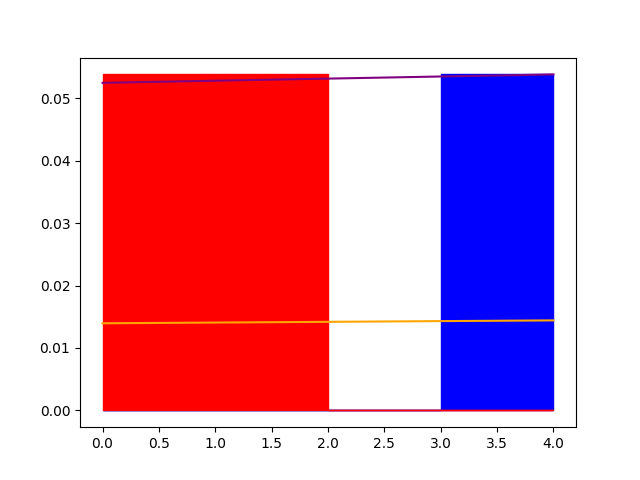
ax.fill_between(range(len(df['home'])), height * df['home'], step='post', color='blue')
ax.fill_between(range(len(df['work'])), height * df['work'], step='post', color='red')
plt.show()
数据如下所示:
date app_1 app_2 user bar grocers home lunch park relatives work
0 2017-08-29 14:00:00 0.013953 0.052472 user_1 0.0 0.0 0.0 0.0 0.0 0.0 1.0
1 2017-08-29 14:15:00 0.014070 0.052809 user_1 0.0 0.0 0.0 0.0 0.0 0.0 1.0
2 2017-08-29 14:30:00 0.014186 0.053146 user_1 1.0 0.0 0.0 0.0 0.0 0.0 0.0
3 2017-08-29 14:45:00 0.014302 0.053483 user_1 0.0 0.0 1.0 0.0 0.0 0.0 0.0
4 2017-08-29 15:00:00 0.014419 0.053820 user_1 0.0 0.0 1.0 0.0 0.0 0.0 0.0
看起来像这样: