import pandas as pd
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
pd.set_option('display.max_colwidth', -1)
data = pd.read_csv(...)
data.columns
鉴于上面的代码,我希望看到这个数据集中668列的完整列表。相反,输出被截断,如下所示:
Index(['VIN_SIGNI_PATTRN_MASK', 'NCI_MAK_ABBR_CD', 'MDL_YR', 'VEH_TYP_CD',
'VEH_TYP_DESC', 'MAK_NM', 'MDL_DESC', 'TRIM_DESC', 'OPT1_TRIM_DESC',
'OPT2_TRIM_DESC',
...
'EPA_SMART_WAY_DESC', 'MA_COLL_SYMB', 'MA_COMP_SYMB', 'MA_BASE_SYMB',
'MA_VSR_SYMB', 'MA_PERFORMANCE_IND', 'MA_ROLL_IND', 'PROACTIVE_IND',
'MAK_CD', 'MDL_CD'],
dtype='object', length=668)
为什么我看不到所有668列?
因为您正在更改输出,而不是Python本身截断输出的方式。
例如:显示。最大行数和显示。max_columns设置帧完全打印时显示的最大行数和列数。截断的行将替换为省略号。https://pandas.pydata.org/pandas-docs/stable/user_guide/options.html#frequently-使用选项
与此相反,只需执行list(data.columns)

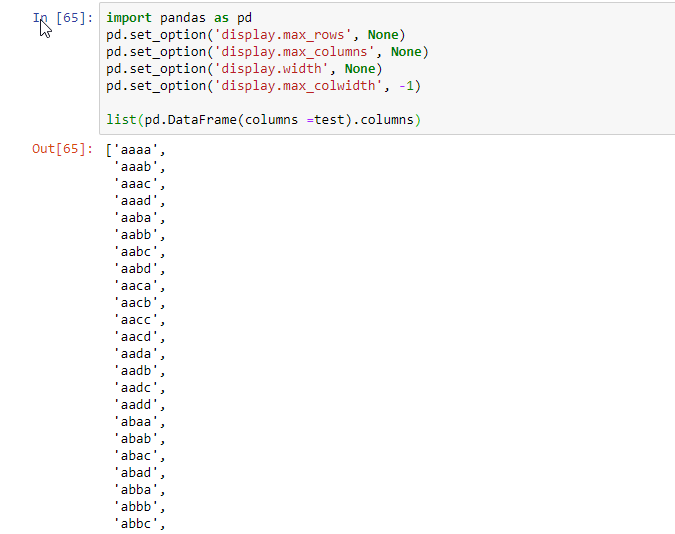
你的解决方案对我有用。。。(可以滚动到最后一列)
import pandas as pd
import numpy as np
print(pd.__version__)
pd.set_option('display.max_columns', None)
df = pd.DataFrame(np.random.rand(10, 668))
df