
我正试图用Python和BeautifulSoup来浏览ETF每日信息。我的代码从《华尔街日报》页面提取信息。但我的重试次数最多。我在一次运行中成功地刮取了10只ETF,但现在我正在尝试刮取新的ETF,但我不断收到以下代理错误:
ProxyError:HTTPSConnectionPool(host='quotes.wsj.com',port=443):url:/etf/ACWI超过了最大重试次数(由ProxyError('无法连接到代理'),错误('隧道连接失败:需要407代理授权',))
我想知道是否有办法处理这个错误。我的代码如下:
import requests
from bs4 import BeautifulSoup
import pandas as pd
ticker_list = ["ACWI", "AGG", "EMB", "VTI", "GOVT", "IEMB", "IEMG", "EEM", "PCY", "CWI", "SPY", "EMLC"]
x = len(ticker_list)
date, open_list, previous_list, assets_list, nav_list, shares_list = ([] for a in range(6))
for i in range(0,x):
ticker = ticker_list[i]
date.append("20181107")
link = "https://quotes.wsj.com/etf/" + ticker
proxies = {"http":"http://username:password@proxy_ip:proxy_port"}
r = requests.get(link, proxies=proxies)
#print (r.content)
html = r.text
soup = BeautifulSoup(html, "html.parser")
aux_list, aux_list_2 = ([] for b in range(2))
for data in soup.find_all("ul", attrs={"class":"cr_data_collection"}):
for d in data:
if d.name == "li":
aux_list.append(d.text)
print(d.text)
print ("Start List Construction!")
k = len(aux_list)
for j in range(0,k):
auxiliar = []
if "Volume" in aux_list[j]:
auxiliar = aux_list[j].split()
volume = auxiliar[1]
if "Open" in aux_list[j]:
auxiliar = aux_list[j].split()
open_price = auxiliar[1]
open_list.append(auxiliar[1])
if "Prior Close" in aux_list[j]:
auxiliar = aux_list[j].split()
previous_price = auxiliar[2]
previous_list.append(auxiliar[2])
if "Net Assets" in aux_list[j]:
auxiliar = aux_list[j].split()
net_assets = auxiliar[2] # In Billions
assets_list.append(auxiliar[2])
if "NAV" in aux_list[j]:
auxiliar = aux_list[j].split()
nav = auxiliar[1]
nav_list.append(auxiliar[1])
if "Shares Outstanding" in aux_list[j]:
auxiliar = aux_list[j].split()
shares = auxiliar[2] # In Millions
shares_list.append(auxiliar[2])
print ("Open Price: ", open_price, "Previous Price: ", previous_price)
print ("Net Assets: ", net_assets, "NAV: ", nav, "Shares Outstanding: ", shares)
print nav_list, len(nav_list)
print open_list, len(open_list)
print previous_list, len(previous_list)
print assets_list, len(assets_list)
print shares_list, len(shares_list)
data = {"Fecha": date, "Ticker": ticker_list, "NAV": nav_list, "Previous Close": previous_list, "Open Price": open_list, "Net Assets (Bn)": assets_list, "Shares (Mill)": shares_list}
df = pd.DataFrame(data, columns = ["Fecha", "Ticker", "Net Assets", "Previous Close", "Open Price", "NAV", "Shares"])
df
df.to_excel("C:\\Users\\labnrodriguez\\Documents\\out_WSJ.xlsx", sheet_name="ETFs", header = True, index = False) #, startrow = rows)
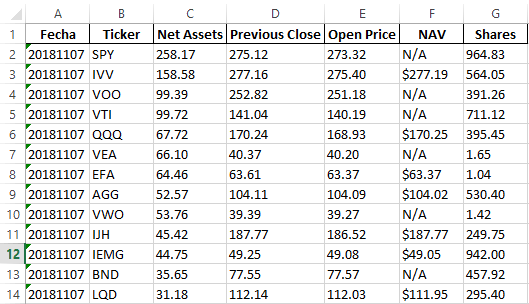
输出为Excel文件中的下表:
首先,你不需要刮取他们的数据。etfdb api节点。js软件包为您提供ETF数据:
请看我的帖子:https://stackoverflow.com/a/53859924/9986657
