
我正在尝试使用一个CNN架构来对文本句子进行分类。 网络的体系结构如下:
text_input = Input(shape=X_train_vec.shape[1:], name = "Text_input")
conv2 = Conv1D(filters=128, kernel_size=5, activation='relu')(text_input)
drop21 = Dropout(0.5)(conv2)
pool1 = MaxPooling1D(pool_size=2)(drop21)
conv22 = Conv1D(filters=64, kernel_size=5, activation='relu')(pool1)
drop22 = Dropout(0.5)(conv22)
pool2 = MaxPooling1D(pool_size=2)(drop22)
dense = Dense(16, activation='relu')(pool2)
flat = Flatten()(dense)
dense = Dense(128, activation='relu')(flat)
out = Dense(32, activation='relu')(dense)
outputs = Dense(y_train.shape[1], activation='softmax')(out)
model = Model(inputs=text_input, outputs=outputs)
# compile
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
我有一些回调,如early_stopping和reduceLR,当损失没有改善时停止训练,当损失没有减少时降低学习率。
early_stopping = EarlyStopping(monitor='val_loss',
patience=5)
model_checkpoint = ModelCheckpoint(filepath=checkpoint_filepath,
save_weights_only=False,
monitor='val_loss',
mode="auto",
save_best_only=True)
learning_rate_decay = ReduceLROnPlateau(monitor='val_loss',
factor=0.1,
patience=2,
verbose=1,
mode='auto',
min_delta=0.0001,
cooldown=0,
min_lr=0)
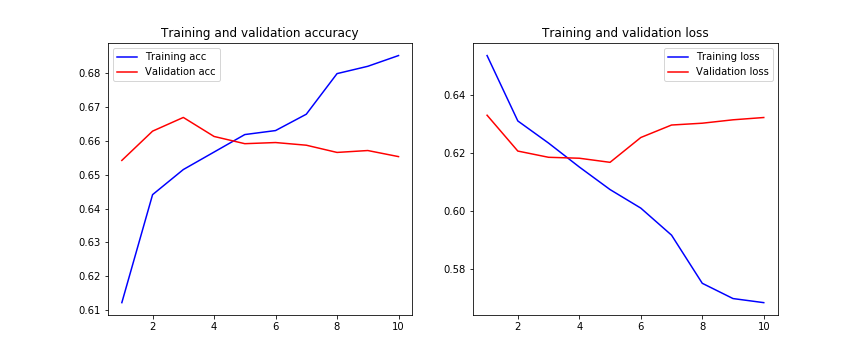
我们可以在这里观察到,验证损失从第5个阶段开始没有改善,训练损失随着每一步都过度拟合。
我想知道我是否在CNN的架构上做错了什么? 是否有足够的脱落层来避免过度拟合? 还有哪些方法可以减少过拟合呢?
有什么建议吗?
提前谢谢你。
过拟合可以由许多因素引起,当你的模型与训练集拟合得太好时,就会发生过拟合。
为了解决这个问题,你可以采取一些方法:
你可以在https://towardsdatascience.com/deep-learning-3-more-on-cnns-handling-overfitting-2bd5d99abe5d阅读
