PostgreSQL Having条件

在本节中,我们将了解PostgreSQL中HAVING 子句的工作原理。
having 子句用于指定组或聚合的搜索条件。它经常与 GROUP BY 子句一起使用,以根据详细条件过滤组或聚合。
PostgreSQL having 子句的语法
PostgreSQL HAVING 子句的基本语法如下:
SELECT column1, aggregate_function (column2)
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
在上面的语法中,我们使用了以下参数:
| 参数 | 描述 |
|---|---|
| GROUP BY 子句 | 它用于返回按 column1 分组的行。 |
| Having 子句 | 它用于定义过滤集合的条件。 |
在PostgreSQL中, HAVING 子句以以下格式工作:

我们不能在HAVING 子句中使用列别名,因为在评估 HAVING 子句时,无法访问SELECT子句中定义的列别名。
having 和 where 子句的区别
让我们看看HAVING 子句和 WHERE 子句之间的区别:
| HAVING 子句 | Where子句 |
|---|---|
| HAVING 子句允许我们根据定义的条件过滤行组。 | WHERE 子句允许我们根据定义的条件过滤行。 |
| HAVING 子句对行组很有用。 | WHERE 子句仅应用于行。 |
PostgreSQL HAVING 子句的例子
让我们看看 PostgreSQL 中 having 子句的一些例子。因此,这里我们将采用我们在 PostgreSQL 教程的早期主题中创建的员工表。

使用 PostgreSQL HAVING 子句的 SUM() 函数示例
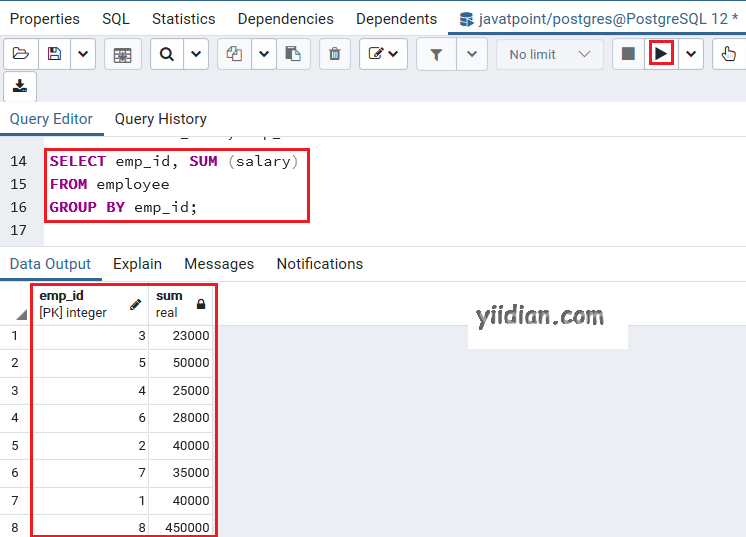
在下面的示例中,我们使用带有 SUM() 函数的 GROUP BY 子句来确定每个员工的总工资:
SELECT emp_id, SUM (salary)
FROM employee
GROUP BY emp_id;
在下面的示例中,我们使用带有SUM()函数的GROUP BY子句来确定每个员工的总工资:
SELECT emp_id, SUM (salary)
FROM employee
GROUP BY emp_id;
执行完上面的命令后,我们会得到下面的输出,它根据每个员工的emp_id显示他们的工资总和。
之后,我们将在上面的命令中添加 HAVING 子句,用于选择工资超过 25000 的员工:
SELECT emp_id, first_name, SUM (salary)
FROM employee
GROUP BY first_name, emp_id
HAVING SUM (salary) > 25000
order by first_name DESC;
执行完上面的命令后,我们会得到如下结果,显示的是那些工资超过25000的员工:
热门文章
优秀文章
