PostgreSQL GroupBy分组

在本节中,我们将了解PostgreSQL中GROUP BY子句的工作原理。我们还看到了 GROUP BY 子句如何与SUM() 函数、COUNT()、JOIN 子句、多列以及没有聚合函数一起工作的示例。
PostgreSQL GROUP BY 条件与 SELECT 命令一起使用,它也可以用来减少结果中的冗余。
PostgreSQL GROUP BY 子句
最重要的是,此子句用于将行拆分为组,其中 GROUP BY 条件跨多个记录收集数据并按一个或多个列设置结果。
并且每个组都可以应用一个聚合函数,例如COUNT()函数用于获取组中的项目数,SUM()函数用于分析项目的总和。
PostgreSQL group by 子句的语法
GROUP BY 子句的基本语法如下:
SELECT column-list
FROM table_name
WHERE [conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
以下是上述语法中使用的参数:
Columns-list:用于选择需要分组的列,可以是column1,column2,...columnN。
我们还可以将 SELECT 命令的附加条件与 GROUP BY 子句一起使用。
在PostgreSQL中,GROUP BY 子句的作用如下:
PostgreSQL GROUP BY 子句示例
为了更好地理解,我们将使用我们在 PostgreSQL 教程的前面部分中创建的Employee表。

- 不使用聚合函数的 GROUP BY 子句示例
在这里,我们将使用GROUP BY子句而不应用聚合函数。所以,我们使用下面的命令,它从employee表中获取记录,并通过emp_id对结果进行分组。
SELECT emp_id
FROM employee
GROUP BY emp_id;
执行上述命令后,我们将得到以下结果:
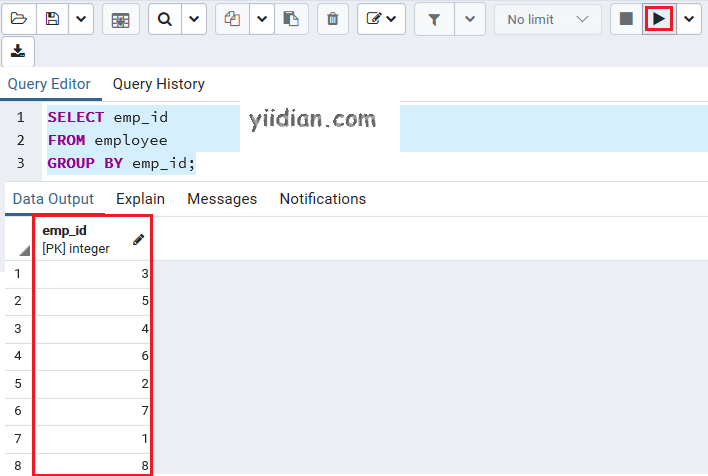
在上面的示例中,GROUP BY子句的作用类似于DISTINCT条件,它帮助我们从结果集中删除匹配的行。
- 使用 PostgreSQL GROUP BY Clasue 的 SUM() 函数示例
在这里,我们使用带有GROUP BY条件的聚合函数。
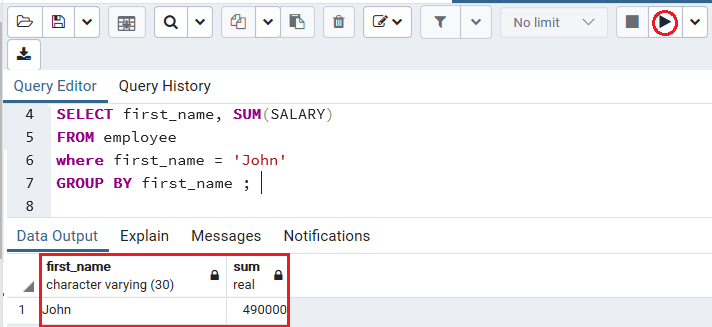
例如,如果我们想获取员工表中first_name为John的薪水总和。因此,我们使用带有 GROUP BY 子句的where子句来获取 John 的薪水。
下面的命令用于在GROUP BY条件的帮助下获取John 的工资总和:
SELECT first_name, SUM(SALARY)
FROM employee
where first_name = 'John'
GROUP BY first_name ;
执行上述命令后,我们将得到以下结果:
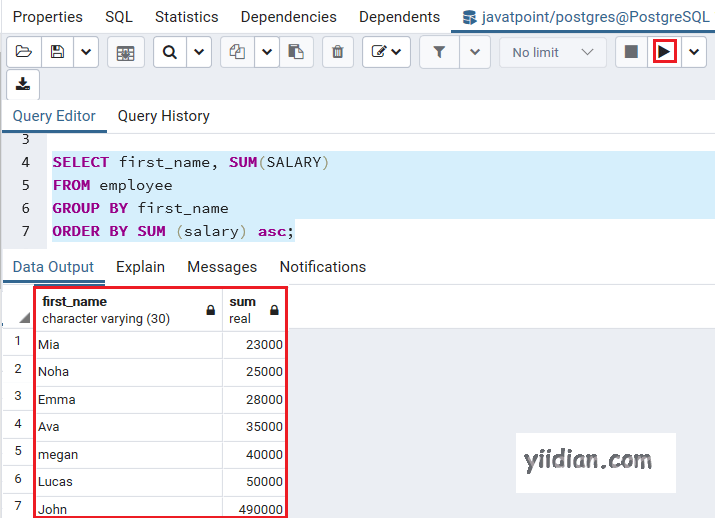
在下面的命令中,我们使用ORDER BY条件通过GROUP BY子句以升序显示所有员工的工资:
SELECT first_name, SUM(SALARY)
FROM employee
GROUP BY first_name
ORDER BY SUM (salary) asc;
执行上述命令后,我们将得到以下输出:
热门文章
优秀文章
