PostgreSQL Drop Index删除索引

在本节中,我们将了解PostgreSQL Drop Index的工作原理和Drop index 命令的示例。
为什么我们使用 PostgreSQL Drop index 命令?
在PostgreSQL中,Drop index命令用于删除现有索引。如果我们删除一个索引,它会提高性能。
PostgreSQL 删除索引命令的语法
删除索引命令的语法如下:
DROP INDEX [ CONCURRENTLY]
[ IF EXISTS ] index_name
[ CASCADE | RESTRICT ];
在上面的语法中,我们使用了以下参数,如下表所示:
| 参数 | 描述 |
|---|---|
| index_name | 它用于定义我们要删除它的索引的名称。并且应该写在DROP INDEX命令之后。
|
| IF EXISTS | 如果我们尝试删除不存在的索引,则会在输出中引发错误。因此,我们可以使用IF EXISTS选项来解决这个错误。
|
| CASCADE | CASCADE选项用于索引,其中包含依赖对象。而CASCADE 选项会自动移除这些对象以及依赖这些对象的所有对象。
|
| RESTRICT | RESTRICT选项通知 PostgreSQL在任何对象依赖索引时删除索引。默认情况下,DROP INDEX命令使用RESTRICT选项。 |
注意事项:
如果我们执行DROP INDEX命令,PostgreSQL 会获得表的独占锁并阻止其他访问,直到索引删除完成。
在这种情况下,我们可以使用CONCURRENTLY选项强制允许语句等到矛盾事务结束后再删除索引。
DROP INDEX CONCURRENTLY包含一些边界:
- 使用DROP INDEX CONCURRENTLY时不支持CASCADE选项。
- 如果我们同时使用DROP INDEX,也不支持在事务块中实现。
PostgreSQL 删除索引示例
让我们看一个例子来理解PostgreSQL DROP Index命令的工作原理。
为此,我们将使用我们在 PostgreSQL 教程的前面部分中创建的Employee表。
Employee 表包含各种列,例如emp_id、employee_name、phone 和 address。
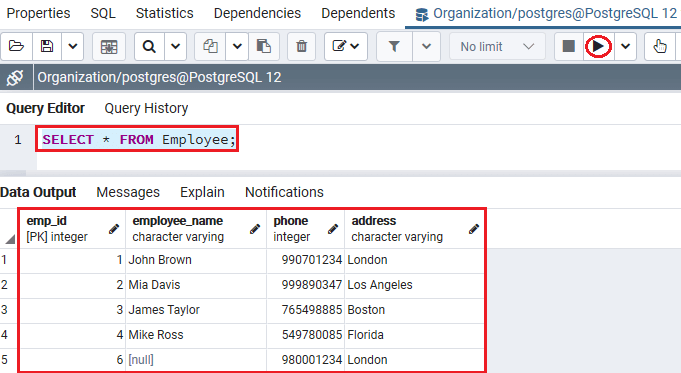
执行下面的SELECT命令后,我们可以看到Employee表中存在的数据,如下面的屏幕截图所示:
SELECT * FROM Employee;
执行上述命令后,我们将得到以下输出:
现在,我们为Employee表的Address列创建一个索引,如以下命令所示:
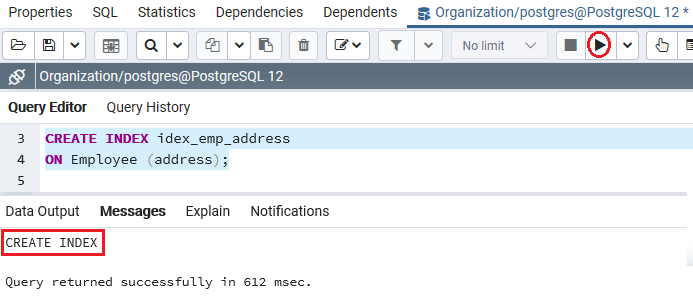
CREATE INDEX idex_emp_address
ON Employee (address);
执行完上面的命令后,我们会得到下面的消息窗口,显示Idex_emp_address已经创建成功。
正如我们在以下示例中所做的那样,以下命令用于识别地址为Boston的员工:
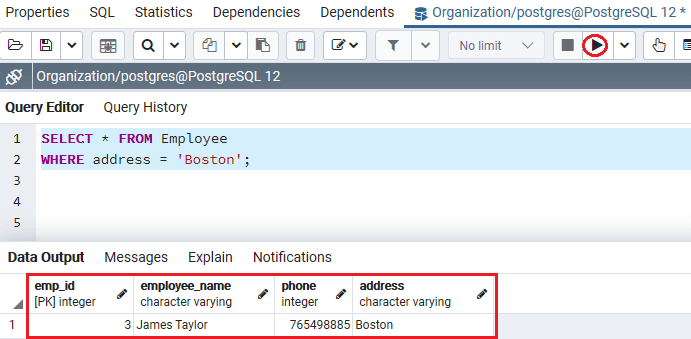
SELECT * FROM Employee
WHERE address = 'Boston';
执行上述命令后,我们将得到以下输出,我们在其中成功识别出地址为波士顿的员工。
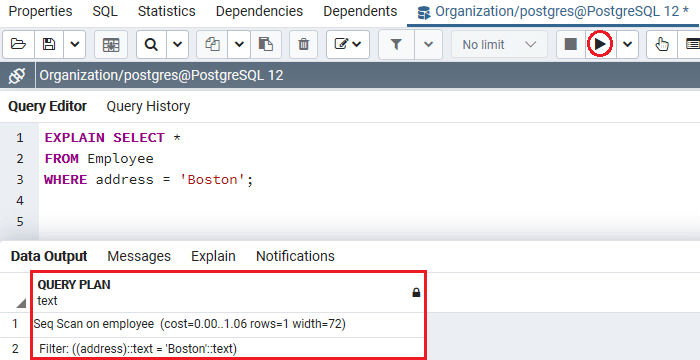
在上面的命令中,我们没有使用idex_emp_address索引,它是在 PostgreSQL 索引教程的 PostgreSQL 创建索引的前面部分指定的,如下面的EXPLAIN命令所示:
EXPLAIN SELECT *
FROM Employee
WHERE address = 'Boston';
执行上述命令后,我们将得到如下输出,其中显示了Employee表的查询计划。
发生这种情况是因为查询开发人员认为扫描整个表来定位行是理想的。
因此,在这种情况下,使用idex_emp_address是不利的;这就是我们在以下命令的帮助下删除它的原因:
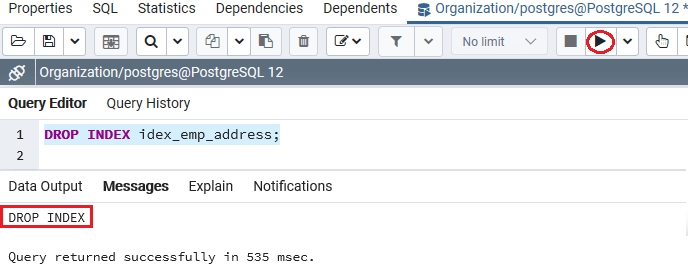
DROP INDEX idex_emp_address;
执行上述命令后,我们会得到如下信息,显示已成功删除idex_emp_address索引。
热门文章
优秀文章
