MySQL UPSERT

UPSERT 是用于管理数据库的 DBMS 软件的基本功能之一。此操作允许 DML 用户向表中插入新记录或更新现有数据。UPSERT 由两个名为UPDATE和INSERT的单词组合而成。前两个字母,即UP 代表UPDATE 而SERT 代表INSERT。UPSERT 是一个原子操作,这意味着它是一个一步完成的操作。例如,如果一条记录是新的,它将触发 INSERT 命令。但是,如果它已经存在于表中,那么这个操作将执行一个UPDATE 语句。
默认情况下,MySQL为 INSERT 提供了 ON DUPLICATE KEY UPDATE 选项,它完成了这个任务。但是,它还包含一些其他语句来实现此目标,例如 INSERT IGNORE 或 REPLACE。我们将详细学习并查看所有这些解决方案。
一、MySQL UPSERT 示例
我们主要可以通过以下三种方式来执行MySQL UPSERT操作:
- UPSERT 使用 INSERT IGNORE
- 使用 REPLACE 进行 UPSERT
- UPSERT 使用 INSERT ON DUPLICATE KEY UPDATE
二、UPSERT 使用 INSERT IGNORE
当我们执行无效行的插入操作时, INSERT IGNORE 语句用于忽略我们的执行错误。例如,主键列不能让我们存储重复值。如果我们尝试使用表中已存在的相同主键插入新记录,我们将收到错误消息。但是,如果我们使用 INSERT IGNORE 命令执行此操作,它将生成警告而不是错误。
以下是在 MySQL中使用INSERT IGNORE语句的语法:
INSERT IGNORE INTO table_name (column_names)
VALUES ( value_list), ( value_list) .....;
MySQL 插入忽略示例
让我们了解 MySQL 中 INSERT IGNORE 语句的工作原理。首先,我们需要使用以下语句创建一个名为“Student”的表:
CREATE TABLE Student (
Stud_ID int AUTO_INCREMENT PRIMARY KEY,
Name varchar(45) DEFAULT NULL,
Email varchar(45) NOT NULL UNIQUE,
City varchar(25) DEFAULT NULL
);
UNIQUE 约束_确保我们不能将重复值保留在电子邮件列中。接下来,需要将记录插入表中。以下语句用于将数据添加到表中:
INSERT INTO Student(Stud_ID, Name, Email, City)
VALUES (1,'Stephen', 'stephen@javatpoint.com', 'Texas'),
(2, 'Joseph', 'Joseph@javatpoint.com', 'Alaska'),
(3, 'Peter', 'Peter@javatpoint.com', 'California');
现在,我们可以验证插入使用SELECT语句进行操作:
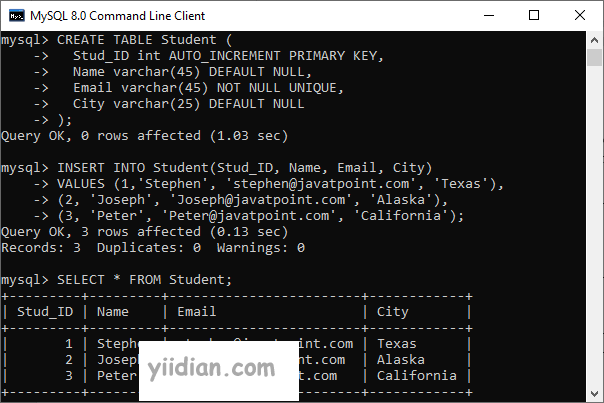
mysql> SELECT * FROM Student;
我们将获得以下输出,其中表中有三行:
现在,我们将执行以下语句以将两条记录添加到表中:
INSERT INTO Student(Stud_ID, Name, Email, City)
VALUES (4,'Donald', 'donald@javatpoint.com', 'New York'),
(5, 'Joseph', 'Joseph@javatpoint.com', 'Chicago');
执行上述语句后,我们将看到错误:ERROR 1062 (23000): Duplicate entry ' Joseph@javatpoint.com ' for key 'student.Email' 因为Email字段违反了 UNIQUE 约束。
但是,当我们使用 INSERT IGNORE 命令执行相同的语句时,我们没有收到任何错误。相反,我们只会收到警告。
INSERT IGNORE INTO Student(Stud_ID, Name, Email, City)
VALUES (4,'Donald', 'donald@javatpoint.com', 'New York'),
(5, 'Joseph', 'Joseph@javatpoint.com', 'Chicago');
MySQL 将产生一条消息:添加了一行,而忽略了另一行。
1 row affected, 1 warning(s): 1062 Duplicate entry for key email.
Records: 2 Duplicates: 1 Warning: 1
我们可以使用SHOW WARNINGS命令查看详细的警告:

因此,如果有一些重复并且我们使用 INSERT IGNORE 语句,MySQL 会给出警告而不是发出错误,并将剩余的记录添加到表中。
三、使用 REPLACE 进行 UPSERT
在某些情况下,我们希望将现有记录更新到表中以保持更新。如果我们为此目的使用标准插入查询,它将为 PRIMARY KEY 错误提供重复条目。在这种情况下,我们将使用 REPLACE 语句来执行我们的任务。当我们使用 REPLACE 命令时,有两个可能的事件发生:
- 如果没有找到与现有数据行匹配的值,则执行标准 INSERT 语句。
- 如果旧记录与新记录匹配,则替换命令将删除现有行,然后执行正常的 INSERT 语句,将新记录添加到表中。
在 REPLACE 语句中,更新分两步执行。首先,它将删除现有记录,然后添加新更新的记录,类似于标准的 INSERT 命令。因此,我们可以说 REPLACE 语句执行两个标准功能,DELETE和INSERT。
MySQL中REPLACE语句的语法如下:
REPLACE [INTO] table_name(column_list)
VALUES(value_list);
示例
让我们借助一个真实的例子来理解它。在这里,我们将使用我们之前创建的包含以下数据的Student表:
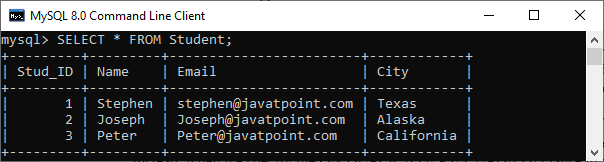
现在,我们将使用 REPLACE 语句将id = 2 的学生所在城市更新为新城市Los Angeles。为此,请执行以下语句:
REPLACE INTO Student(Stud_ID, Name, Email, City)
VALUES(2, 'Joseph', 'joseph@javatpoint.com', 'Los Angeles');
执行成功后,我们会得到如下输出:
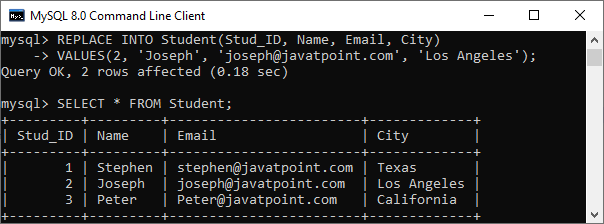
在上图中,我们可以看到“2 row(s) affected”的消息,而我们只更新了单行的值。这是因为 REPLACE 命令首先删除了记录,然后将新记录添加到表中。因此,消息显示“2 row(s) affected”。
四、UPSERT 使用 INSERT ON DUPLICATE KEY UPDATE
到目前为止,我们已经看到了两个 UPSERT 命令,但它们有一些限制。INSERT IGNORE 语句仅忽略重复错误而不对表进行任何修改。并且 REPLACE 方法检测到 INSERT 错误,但它会在添加新记录之前删除该行。因此,直到现在我们仍在寻找更精细的解决方案。
因此,我们使用更精细的解决方案作为INSERT ON DUPLICATE KEY UPDATE语句。这是一种非破坏性方法,这意味着它不会删除重复的行。相反,当我们在 SQL 语句中指定 ON DUPLICATE KEY UPDATE 子句并且行会导致UNIQUE 或 PRIMARY KEY索引列中出现重复错误值时,就会更新现有行。
INSERT INTO table (column_names)
VALUES (data)
ON DUPLICATE KEY UPDATE
column1 = expression, column2 = expression...;
示例
让我们借助一个真实的例子来理解它。在这里,我们将使用我们之前创建的学生表。现在,使用以下查询在表中再添加一行:
MySQL 中Insert on Duplicate Key Update语句的语法如下:
INSERT INTO Student(Stud_ID, Name, Email, City)
VALUES (4,'John', 'john@javatpoint.com', 'New York');
查询将成功添加一条记录到表中,因为它没有任何重复值。
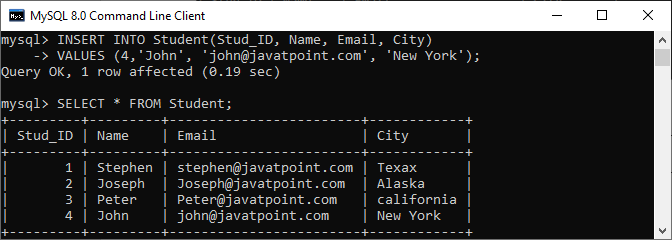
接下来,执行以下 MySQL UPSERT 命令更新Stud_ID列中的重复记录:
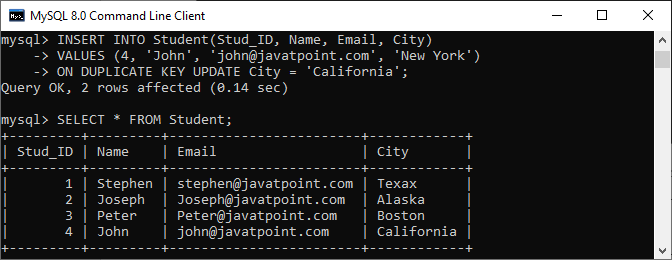
INSERT INTO Student(Stud_ID, Name, Email, City)
VALUES (4, 'John', 'john@javatpoint.com', 'New York')
ON DUPLICATE KEY UPDATE City = 'California';
成功执行后,MySQL 给出以下消息:
Query OK, 2 rows affected.
在输出中,我们可以看到行 id=4已经存在。因此,该查询仅将City New York更新为California。
热门文章
优秀文章
