MySQL REGEXP_SUBSTR()函数

MySQL 中的 REGEXP_SUBSTR() 函数用于模式匹配。此函数从输入字符串中返回与给定正则表达式模式匹配的子字符串。如果没有找到匹配项,它将返回 NULL。如果表达式或模式为 NULL,则函数将返回 NULL。
REGEXP_SUBSTR() 与 SUBSTRING 函数相同,但不是仅提取给定的子字符串,此函数还允许我们在字符串中搜索正则表达式模式。
一、MySQL REGEXP_SUBSTR()函数 语法
以下是在MySQL中使用此函数的基本语法:
REGEXP_SUBSTR (expression, pattern [, position[, occurrence[, match_type]]])
参数说明
expression:这是一个输入字符串,我们将通过正则表达式对其进行搜索。
pattern:它表示子字符串的正则表达式模式。
REGEXP_SUBSTR() 函数也使用下面给出的可选参数:
pos:用于指定表达式在字符串中的位置开始搜索。如果我们省略这个参数,它会从位置 1 开始。
发生:它用于指定我们要搜索的匹配项。如果我们省略此参数,则使用第一次出现。
match_type:它是一个字符串,可以让我们细化正则表达式。它使用以下可能的字符来执行匹配。
- c:表示区分大小写的匹配。
- i:表示不区分大小写的匹配。
- E:用于使用子表达式提取子字符串。
- m:它表示一种多行模式,可以识别字符串中的行终止符。默认情况下,此函数匹配字符串开头和结尾的行终止符。
- n:用于修改 . (点)字符以匹配行终止符。默认情况下,它将停在一行的末尾。
- u:它表示仅通过 .、^ 和 $ 匹配运算符识别换行符的 Unix 行尾。
二、MySQL REGEXP_SUBSTR()函数 示例
以下语句解释了 MySQL 中 REGEXP_SUBSTR 函数的基本示例。
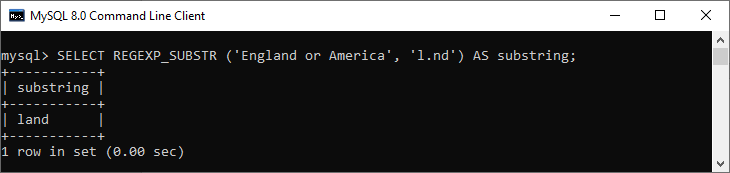
mysql> SELECT REGEXP_SUBSTR ('England or America', 'l.nd') AS substring;
此语句找到匹配项并返回以下输出:
假设在输入字符串中找到多个匹配项。在这种情况下,默认返回匹配的子字符串的第一次出现。但是,如果需要,我们也可以指定另一个事件。请参阅以下声明:
mysql> SELECT REGEXP_SUBSTR ('Lend for land', 'l.nd') AS substring;
此语句找到匹配项并返回匹配的子字符串的第一个匹配项,因为我们没有指定任何特定的匹配项。请参阅以下输出:

如果输入字符串和模式(子字符串)字符串不匹配,则此函数返回 NULL 值。请参见以下示例:
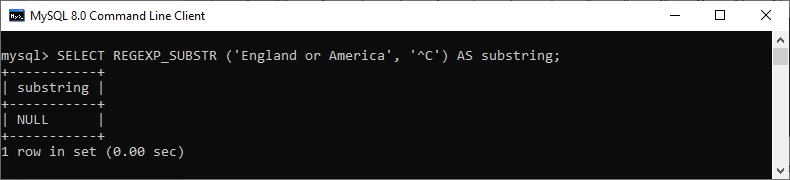
mysql> SELECT REGEXP_SUBSTR ('England or America', '^C') AS substring;
输出结果:
如果我们想通过指定起始位置来返回子字符串,我们可以使用 REGEX_SUBSTR 函数,如下所示:
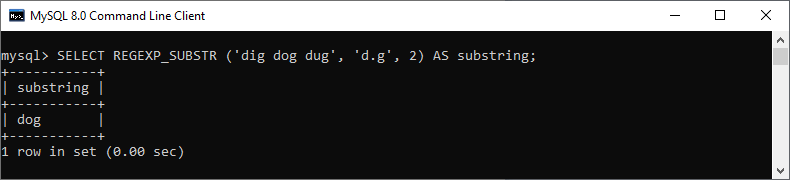
mysql> SELECT REGEXP_SUBSTR ('dig dog dug', 'd.g', 2) AS substring;
在此语句中,我们将起始位置指定为 2。执行此查询,我们将获得以下输出,其中我们可以看到未返回匹配子字符串的第一个位置。
让我们看另一个例子来更清楚地理解它:
mysql> SELECT
REGEXP_SUBSTR('dig dog dug', 'd.g', 1) AS 'Position 1',
REGEXP_SUBSTR('dig dog dug', 'd.g', 2) AS 'Position 2',
REGEXP_SUBSTR('dig dog dug', 'd.g', 6) AS 'Position 6';
输出结果:

如果我们想指定返回匹配子字符串的具体出现,我们可以使用这个函数如下:
mysql> SELECT REGEXP_SUBSTR ('dig dog dug', 'd.g', 1, 3) AS 'Occurrence 3';
在本例中,我们指定匹配子串的起始位置为 1,匹配子串的出现次数为 3。因此我们将得到以下输出:

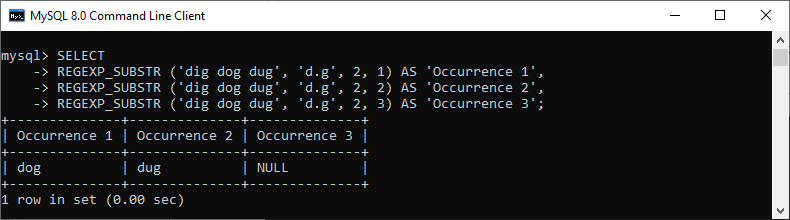
这是另一个示例,我们将起始位置指定为 2,出现次数为 1、2 和 3。
mysql> SELECT
REGEXP_SUBSTR ('dig dog dug', 'd.g', 2, 1) AS 'Occurrence 1',
REGEXP_SUBSTR ('dig dog dug', 'd.g', 2, 2) AS 'Occurrence 2',
REGEXP_SUBSTR ('dig dog dug', 'd.g', 2, 3) AS 'Occurrence 3';
此函数将给出以下输出,因为起始位置是在第一次出现之后出现的。因此,此函数假定出现 2 为出现 1,出现 3 为出现 2。然后再没有发现任何出现,因此出现 3 的结果变为 NULL。
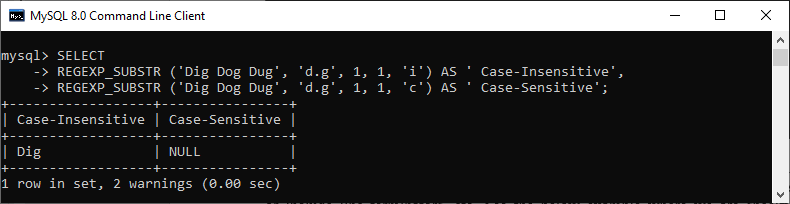
我们可以提供一个额外的参数来使用匹配类型参数来优化正则表达式。例如,我们可以使用它来验证匹配是否区分大小写或包含行终止符。请参阅下面的示例,其中我们指定了区分大小写和不区分大小写的匹配:
mysql> SELECT
REGEXP_SUBSTR ('Dig Dog Dug', 'd.g', 1, 1, 'i') AS ' Case-Insensitive',
REGEXP_SUBSTR ('Dig Dog Dug', 'd.g', 1, 1, 'c') AS ' Case-Sensitive';
输出结果:
热门文章
优秀文章
