MySQL ngram全文解析器

在本文中,我们将学习 MySQL ngram 全文解析器的使用,该解析器支持对日语、汉语和韩语等表意语言进行全文搜索。
内置的 MySQL 全文解析器使用分隔符作为单词之间的空格,确定单词的开头和结尾。全文解析器在处理日文、中文和韩文等表意语言时存在局限性,因为它们不使用单词分隔符。
MySQL提供了 ngram 全文解析器来解决这个问题。在 MySQL版本 5之后,MySQL 提供了 ngram 全文解析器作为内置服务器插件。与其他内置插件类似,MySQL 会在数据库服务器启动时自动加载此插件。MySQL 中的 InnoDB 和 MyISAM 存储引擎都支持 ngram 全文解析器。
根据其在 MySQL 中的定义,ngram 是来自给定文本序列的多个字符的连续序列。它的主要功能是将一个文本序列标记为一个连续的 n 个字符序列。例如,通过使用 ngram 全文解析器,我们可以将字符串“ java ”标记为不同的N值,如下所示:
N = 1: 'j', 'a', 'v', 'a'
N = 2: 'ja', 'av', 'va'
N = 3: 'jav', 'ava'
N = 4: 'java'
一、使用 ngram Parser 创建 FULLTEXT 索引
我们可以通过在CREATE TABLE、ALTER TABLE或 CREATE INDEX 语句中指定WITH PARSER ngram来使用ngram 解析器创建 FULLTEXT 索引。
考虑以下示例,该示例创建一个名为“ articles ”的表,并使用 ngram 全文解析器添加标题和正文列。
mysql> CREATE TABLE articles (
id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(150),
body TEXT,
FULLTEXT (title, body) WITH PARSER ngram
) ENGINE=INNODB CHARACTER SET UTF8MB4;
接下来,我们将使用SET NAMES语句将字符集设置为UTF8MB4,如下所示:
mysql> SET NAMES UTF8MB4;
接下来,将示例数据(简体中文文本)插入到该表中,如下所示:
mysql> INSERT INTO articles (title, body) VALUES
('?????', '??????????????????'),
('???????', '???????????');
第四,我们将使用以下语句来查看 ngram 如何标记数据:
mysql> SET GLOBAL innodb_ft_aux_table = "employeedb/articles";
mysql> SELECT * FROM
INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE
ORDER BY doc_id, position;
我们将得到以下结果:
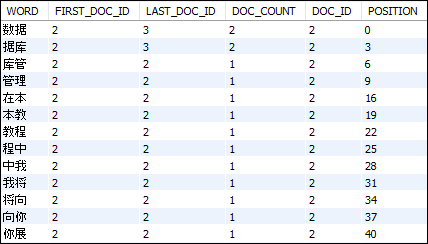
这种类型的语句有助于进行故障排除。例如,如果我们搜索一个不包含它的词,则该词假定为停用词并且可能不会被索引,或者可能是其他原因。
二、设置 ngram 令牌大小
在前面的示例中,我们可以看到默认情况下,ngram 中的令牌大小 (n) 为 2。如果要更改默认令牌大小,我们需要使用ngram_token_size配置选项,其值范围在 1 到 10 之间。需要注意的是,较小的令牌大小使全文搜索索引更小,并且还提供快速搜索。
ngram_token_size 是一个只读变量,因此我们只能使用以下两个选项来设置它的值:
1. 在启动字符串中:
mysqld --ngram_token_size=1
2.在配置文件中:
[mysqld]
ngram_token_size=1
三、ngram Parser 中的空间处理
解析时在 ngram 解析器中消除空间。例如:
- "ab cd" 被解析为 "ab", "cd"
- “a bc”被解析为“bc”
四、ngram 解析器短语搜索
MySQL 将短语搜索转换为 ngram 短语搜索。例如,我们有一个短语搜索“abc”,它被转换为“ab bc”,返回包含“abc”和“ab bc”的结果。
如果我们有一个搜索短语“abc def”被转换为“ab bc de ef”,它会返回包含“abc def”和“ab bc de ef”的结果。它不返回包含“abcdef”的文档。
下面的语句显示了对短语 ?? 的搜索。在文章表中:
SELECT id, title, body
FROM articles
WHERE MATCH (title, body) AGAINST ('??');
输出结果为:

五、使用 ngram 处理不同的搜索模式
在这里,我们将使用以下模式使用 ngram 处理搜索结果:
自然语言模式
NATURAL LANGUAGE 搜索模式将搜索词转换为 ngram 值的并集。例如,如果token size为2,则搜索词“mysql”可以转换为my ys sq和ql。请参阅以下声明:
mysql> SELECT * FROM articles
WHERE MATCH (title, body)
AGAINST ('?????' IN NATURAL LANGUAGE MODE);
输出结果为:

布尔模式
布尔搜索模式将搜索词转换为 ngram 短语搜索。请参阅以下声明:
mysql> SELECT * FROM articles
WHERE MATCH (title, body)
AGAINST ('?????' IN BOOLEAN MODE);
输出结果为:

六、ngram 解析器通配符搜索
当我们在 ngram 解析器中使用通配符进行搜索时,可能会返回意想不到的结果。因为 ngram FULLTEXT 索引只包含 ngram,所以它不知道术语的开头。
以下规则用于使用带有通配符的 ngram 全文索引执行搜索:
1. 如果ngram token 的大小比通配符中的prefix term 长,则查询返回所有包含以prefix term 开头的ngram token 的文档。例如:
mysql> SELECT * FROM articles
WHERE MATCH (title, body) AGAINST ('my*');
输出结果为:

2. 如果ngram token 的大小小于通配符中的前缀词,MySQL 会将前缀词转换为ngram 短语,通配符操作符被忽略。例如
mysql> SELECT * FROM articles
WHERE MATCH (title, body) AGAINST ('mysql');
我们将得到以下结果,其中术语“mysql”被转换为 ngram 短语:“my”“ys”“sq”“ql”。

七、在 ngram Parser 中处理停用词
ngram 解析器比较停用词列表中条目的单词。如果它们相等,则从索引中排除该词。
ngram 解析器以不同的方式处理停用词。它排除包含停用词的标记,而不是排除等于停用词列表的标记。
例如,如果 ngram_token_size 为 2 并且文档包含“a,b”,则 ngram 解析器将它们标记为“a”和“,b”。如果逗号 (",") 是停用词,则 "a," 和 ",b" 都将被排除,因为它们包含逗号。
请注意,ngram 解析器使用英语的默认停用词列表。如果我们想使用其他语言,我们必须创建自己的。
热门文章
优秀文章
