Java XPath解析器 查询XML文档

Java XPath解析器 查询XML文档的示例
需要解析的文件input.xml
<?xml version = "1.0"?>
<class>
<student rollno = "393">
<firstname>dinkar</firstname>
<lastname>kad</lastname>
<nickname>dinkar</nickname>
<marks>85</marks>
</student>
<student rollno = "493">
<firstname>Vaneet</firstname>
<lastname>Gupta</lastname>
<nickname>vinni</nickname>
<marks>95</marks>
</student>
<student rollno = "593">
<firstname>jasvir</firstname>
<lastname>singn</lastname>
<nickname>jazz</nickname>
<marks>90</marks>
</student>
</class>
编写Java XPath解析器 查询XML文档的程序
package com.yiidian;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.SAXException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpressionException;
import javax.xml.xpath.XPathFactory;
import java.io.File;
import java.io.IOException;
public class XPathParserDemo {
public static void main(String[] args) throws Exception{
try {
File inputFile = new File("input.xml");
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder dBuilder;
dBuilder = dbFactory.newDocumentBuilder();
Document doc = dBuilder.parse(inputFile);
doc.getDocumentElement().normalize();
XPath xPath = XPathFactory.newInstance().newXPath();
String expression = "/class/student[@rollno = '493']";
NodeList nodeList = (NodeList) xPath.compile(expression).evaluate(
doc, XPathConstants.NODESET);
for (int i = 0; i < nodeList.getLength(); i++) {
Node nNode = nodeList.item(i);
System.out.println("\nCurrent Element :" + nNode.getNodeName());
if (nNode.getNodeType() == Node.ELEMENT_NODE) {
Element eElement = (Element) nNode;
System.out.println("Student roll no : "
+ eElement.getAttribute("rollno"));
System.out.println("First Name : "
+ eElement
.getElementsByTagName("firstname")
.item(0)
.getTextContent());
System.out.println("Last Name : "
+ eElement
.getElementsByTagName("lastname")
.item(0)
.getTextContent());
System.out.println("Nick Name : "
+ eElement
.getElementsByTagName("nickname")
.item(0)
.getTextContent());
System.out.println("Marks : "
+ eElement
.getElementsByTagName("marks")
.item(0)
.getTextContent());
}
}
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (XPathExpressionException e) {
e.printStackTrace();
}
}
}
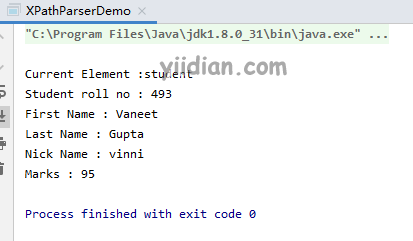
输出结果为:
热门文章
优秀文章
