Java DOM4J解析器 解析XML文档

Java DOM4J解析器 解析XML文档的步骤
以下是使用 DOM4J Parser 解析文档时使用的步骤。
-
导入与 XML 相关的包。
-
创建一个 SAXReader。
-
从文件或流创建文档。
-
通过调用 document.selectNodes() 使用 XPath 表达式获取所需的节点
-
提取根元素。
-
迭代节点列表。
-
检查属性。
-
检查子元素。
导入 XML 相关的包
import java.io.*;
import java.util.*;
import org.dom4j.*;
创建一个文档生成器
SAXBuilder saxBuilder = new SAXBuilder();
从文件或流创建文档
File inputFile = new File("input.txt");
SAXBuilder saxBuilder = new SAXBuilder();
Document document = saxBuilder.build(inputFile);
提取根元素
Element classElement = document.getRootElement();
检查属性
//returns specific attribute
valueOf("@attributeName");
检查子元素
//returns first child node
selectSingleNode("subelementName");
Java DOM4J解析器 解析XML文档的示例
以下是需要解析的input.xml文件
<?xml version = "1.0"?>
<class>
<student rollno = "393">
<firstname>dinkar</firstname>
<lastname>kad</lastname>
<nickname>dinkar</nickname>
<marks>85</marks>
</student>
<student rollno = "493">
<firstname>Vaneet</firstname>
<lastname>Gupta</lastname>
<nickname>vinni</nickname>
<marks>95</marks>
</student>
<student rollno = "593">
<firstname>jasvir</firstname>
<lastname>singn</lastname>
<nickname>jazz</nickname>
<marks>90</marks>
</student>
</class>
编写Java DOM4J解析器 解析XML文档的程序
package com.yiidian;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.Node;
import org.dom4j.io.SAXReader;
import java.io.File;
import java.util.List;
public class DOM4JParserDemo {
public static void main(String[] args) {
try {
File inputFile = new File("input.xml");
SAXReader reader = new SAXReader();
Document document = reader.read( inputFile );
System.out.println("Root element :" + document.getRootElement().getName());
Element classElement = document.getRootElement();
List<Node> nodes = document.selectNodes("/class/student" );
System.out.println("----------------------------");
for (Node node : nodes) {
System.out.println("\nCurrent Element :"
+ node.getName());
System.out.println("Student roll no : "
+ node.valueOf("@rollno") );
System.out.println("First Name : "
+ node.selectSingleNode("firstname").getText());
System.out.println("Last Name : "
+ node.selectSingleNode("lastname").getText());
System.out.println("First Name : "
+ node.selectSingleNode("nickname").getText());
System.out.println("Marks : "
+ node.selectSingleNode("marks").getText());
}
} catch (DocumentException e) {
e.printStackTrace();
}
}
}
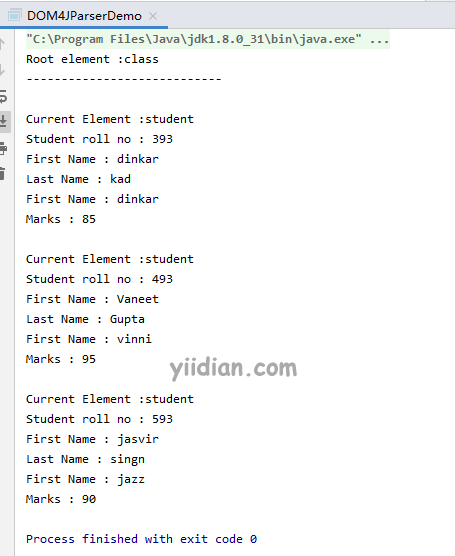
输出结果为:
热门文章
优秀文章
