NodeJs之word文件生成与解析的实现代码
一,介绍与需求
1.1,介绍
1, officegen 模块可以为Microsoft Office 2007及更高版本生成Office Open XML文件。此模块不依赖于任何框架,您不需要安装Microsoft Office,因此您可以将它用于任何类型的 JavaScript 应用程序。输出也是流而不是文件,不依赖于任何输出工具。此模块应适用于支持Node.js 0.10或更高版本的任何环境,包括Linux,OSX和Windows。
2, textract 文本提取节点模块。
3, pdf2json 是一个节点。js模块解析和转换PDF从二进制到json格式,它是用PDF构建的。并通过浏览器外的交互式表单元素和文本内容解析对其进行扩展。其目标是在web服务中包装时启用带有交互式表单元素的服务器端PDF解析,并在作为命令行实用程序使用时启用将本地PDF解析为json文件。
1.2,需求
二,文件生成导出
第一步:安装 officegen
cnpm install officegen --save
第二步:引入officegen
var officegen = require('officegen');
var fs = require('fs');
var docx = officegen('docx');//word
var pptx = officegen('pptx');//pptx
第三步:使用officegen docx
...
docx.on('finalize', function (written) {
console.log('Finish to create Word file.\nTotal bytes created: ' + written + '\n');
});
docx.on('error', function (err) {
console.log(err);
});
...
//var tows = ['id', 'provinceZh', 'leaderZh', 'cityZh', 'cityEn'];//创建一个和表头对应且名称与数据库字段对应数据,便于循环取出数据
var pObj = docx.createP({ align: 'center' });// 创建行 设置居中 大标题
pObj.addText('全国所有城市', { bold: true, font_face: 'Arial', font_size: 18 });// 添加文字 设置字体样式 加粗 大小
// let towsLen = tows.length
let dataLen = data.length
for (var i = 0; i < dataLen; i++) {//循环数据库得到的数据,因为取出的数据格式为
//[{"id" : "101010100","provinceZh" : "北京","leaderZh" : "北京","cityZh" : "北京","cityEn" : "beijing"},{…………},{…………}]
/************************* 文本 *******************************/
// var pObj = docx.createP();//创建一行
// pObj.addText(`(${i+1}), `,{ bold: true, font_face: 'Arial',});
// pObj.addText(`省级:`,{ bold: true, font_face: 'Arial',});
// pObj.addText(`${data[i]['provinceZh']} `,);
// pObj.addText(`市级:`,{ bold: true, font_face: 'Arial',});
// pObj.addText(`${data[i]['leaderZh']} `);
// pObj.addText(`县区:`,{ bold: true, font_face: 'Arial',});
// pObj.addText(`${data[i]['cityZh']}`);
/************************* 表格 *******************************/
let SingleRow = [data[i]['id'], data[i]['provinceZh'], data[i]['leaderZh'], data[i]['cityZh']]
table.push(SingleRow)
}
docx.createTable(table, tableStyle);
var out = fs.createWriteStream('out.docx');// 文件写入
out.on('error', function (err) {
console.log(err);
});
var result = docx.generate(out);// 服务端生成word
res.writeHead(200, {
// 注意这里的type设置,导出不同文件type值不同application/vnd.openxmlformats-officedocument.wordprocessingml.document
"Content-Type": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
'Content-disposition': 'attachment; filename=out' + moment(new Date().getTime()).format('YYYYMMDDhhmmss') + '.docx'
});
docx.generate(res);// 客户端导出word
第四步:抛出接口
router.put('/download/word', function (req, res) {
console.log('exportWord-------------');
docx.on('finalize', function (written) {
console.log('Finish to create Word file.\nTotal bytes created: ' + written + '\n');
});
docx.on('error', function (err) {
console.log(err);
});
let fields = {
id: '',
provinceZh: '',
leaderZh: '',
cityZh: '',
cityEn: ''
}
var table = [
[{
val: "No.",
opts: {
align: "center",
vAlign: "center",
sz: '36',
// cellColWidth: 42,
// b:true,
// sz: '48',
// shd: {
// fill: "7F7F7F",
// themeFill: "text1",
// "themeFillTint": "80"
// },
// fontFamily: "Avenir Book"
}
}, {
val: "省份",
opts: {
align: "center",
vAlign: "center",
sz: '36',
// b:true,
// color: "A00000",
// align: "right",
// shd: {
// fill: "92CDDC",
// themeFill: "text1",
// "themeFillTint": "80"
// }
}
}, {
val: "市",
opts: {
align: "center",
vAlign: "center",
sz: '36',
// cellColWidth: 42,
// b:true,
// sz: '48',
// shd: {
// fill: "92CDDC",
// themeFill: "text1",
// "themeFillTint": "80"
// }
}
}, {
val: "区/县",
opts: {
align: "center",
vAlign: "center",
sz: '36',
// cellColWidth: 42,
// b:true,
// sz: '48',
// shd: {
// fill: "92CDDC",
// themeFill: "text1",
// "themeFillTint": "80"
// }
}
}],
]
var tableStyle = {
tableColWidth: 2400,
tableSize: 24,
tableColor: "ada",
tableAlign: "center",
tableVAlign: "center",
tableFontFamily: "Comic Sans MS",
borders: true
}
MongoDbAction.getFieldsByConditions('AllCity', {}, fields, function (err, data) {//根据需求查询想要的字段
if (err) {
//执行出错
} else {
//var tows = ['id', 'provinceZh', 'leaderZh', 'cityZh', 'cityEn'];//创建一个和表头对应且名称与数据库字段对应数据,便于循环取出数据
var pObj = docx.createP({ align: 'center' });// 创建行 设置居中 大标题
pObj.addText('全国所有城市', { bold: true, font_face: 'Arial', font_size: 18 });// 添加文字 设置字体样式 加粗 大小
// let towsLen = tows.length
let dataLen = data.length
for (var i = 0; i < dataLen; i++) {//循环数据库得到的数据,因为取出的数据格式为
//[{"id" : "101010100","provinceZh" : "北京","leaderZh" : "北京","cityZh" : "北京","cityEn" : "beijing"},{…………},{…………}]
/************************* 文本 *******************************/
// var pObj = docx.createP();//创建一行
// pObj.addText(`(${i+1}), `,{ bold: true, font_face: 'Arial',});
// pObj.addText(`省级:`,{ bold: true, font_face: 'Arial',});
// pObj.addText(`${data[i]['provinceZh']} `,);
// pObj.addText(`市级:`,{ bold: true, font_face: 'Arial',});
// pObj.addText(`${data[i]['leaderZh']} `);
// pObj.addText(`县区:`,{ bold: true, font_face: 'Arial',});
// pObj.addText(`${data[i]['cityZh']}`);
/************************* 表格 *******************************/
let SingleRow = [data[i]['id'], data[i]['provinceZh'], data[i]['leaderZh'], data[i]['cityZh']]
table.push(SingleRow)
}
docx.createTable(table, tableStyle);
var out = fs.createWriteStream('out.docx');// 文件写入
out.on('error', function (err) {
console.log(err);
});
var result = docx.generate(out);// 服务端生成word
res.writeHead(200, {
// 注意这里的type设置,导出不同文件type值不同application/vnd.openxmlformats-officedocument.wordprocessingml.document
"Content-Type": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
'Content-disposition': 'attachment; filename=out' + moment(new Date().getTime()).format('YYYYMMDDhhmmss') + '.docx'
});
docx.generate(res);// 客户端导出word
}
});
});
第五步:前端调用
下载调用方法
downloadWordOper() {
// var url = "http://localhost:8880/api/v1/yingqi/download/word";
// window.location = url;//这里不能使用get方法跳转,否则下载不成功
this.$http(downloadWord()).then((res)=>{
//这里res.data是返回的blob对象
var blob = new Blob([res.data], {type: 'application/vnd.openxmlformats-officedocument.wordprocessingml.document;charset=utf-8'}); //application/vnd.openxmlformats-officedocument.wordprocessingml.document这里表示doc类型
downloadFile(blob,'word','docx')
})
},
downloadFile方法代码如下:
/**
*下载文件
* @param blob :返回数据的blob对象
* @param tagFileName :下载后文件名标记
* @param fileType :文件类 word(docx) excel(xlsx) ppt等
*/
export function downloadFile(blob,tagFileName,fileType) {
var downloadElement = document.createElement('a');
var href = window.URL.createObjectURL(blob); //创建下载的链接
downloadElement.href = href;
downloadElement.download = tagFileName+moment(new Date().getTime()).format('YYYYMMDDhhmmss')+'.'+fileType; //下载后文件名
document.body.appendChild(downloadElement);
downloadElement.click(); //点击下载
document.body.removeChild(downloadElement); //下载完成移除元素
window.URL.revokeObjectURL(href); //释放掉blob对象
}

第六步:下载后的效果
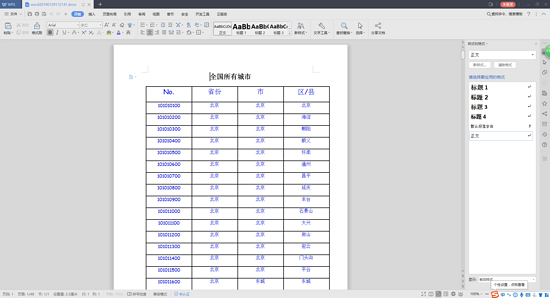
ppt生成下载类似,只是设置的writeHead类型与使用的方法不一样
router.put('/download/createPpt', function (req, res) {
console.log('exportPpt-------------');
pptx.on('finalize', function (written) {
console.log('Finish to create ppt file.\nTotal bytes created: ' + written + '\n');
});
pptx.on('error', function (err) {
console.log(err);
});
let slide1 = pptx.makeNewSlide();//创建一个新幻灯片
slide1.title = "PPT文件";
slide1.addText('Office generator', {
y: 66, x: 'c', cx: '50%', cy: 60, font_size: 48,
color: '0000ff'
});
slide1.addText('Big Red', {
y: 250, x: 10, cx: '70%',
font_face: 'Wide Latin', font_size: 54,
color: 'cc0000', bold: true, underline: true
});
var out = fs.createWriteStream('out.pptx');// 文件写入
out.on('error', function (err) {
console.log('error2===',err);
});
var result = pptx.generate(out);// 服务端生成ppt
res.writeHead(200, {
// 注意这里的type设置,导出不同文件type值不同application/vnd.openxmlformats-officedocument.presentationml.presentation
// "Content-Type": "application/vnd.openxmlformats-officedocument.presentationml.presentation",
// 'Content-disposition': 'attachment; filename=out' + moment(new Date().getTime()).format('YYYYMMDDhhmmss') + '.pptx'
"Content-Type": "application/vnd.openxmlformats-officedocument.presentationml.presentation",
'Content-disposition': 'attachment; filename=surprise.pptx'
});
pptx.generate(res);// 客户端导出ppt
});
三,文件上传解析
3.1,word文档解析
第一步:安装textract
cnpm install textract --save
第二步:引入textract
//引入textract解析word模块
var textract = require('textract');//对于docx文件,您可以使用textract,它将从.docx文件中提取文本。
var fs = require('fs');
第三步:解析文档
function parseWord(excelConfig, res) {
textract.fromFileWithPath(excelConfig.excel_Dir, function (error, text) {
if (error) {
res.status(200).json({
httpCode: 200,
message: '导入解析失败',
data: error,
returnValue: 0
});
} else {
res.status(200).json({
httpCode: 200,
message: '导入成功',
data: {
result: text
},
returnValue: 1
});
}
})
}
第四步:解析后删除文档
fs.unlink(excelConfig.excel_Dir, function (err) {
if (err) throw err;
console.log("删除文件" + excelConfig.excel_Dir + "成功")
})
第五步:抛出接口调用后的效果

3.2,pdf文档解析
第一步:安装pdf2json
cnpm install pdf2json --save
第二步:引入pdf2json
var PDFParser = require("pdf2json");
var fs = require('fs');
第三步:解析文档
function parsePdf(excelConfig, res) {
var pdfParser = new PDFParser(this, 1);
pdfParser.loadPDF(excelConfig.excel_Dir);
pdfParser.on("pdfParser_dataError", errData => {
res.status(200).json({
httpCode: 200,
message: '导入解析失败',
data: errData,
returnValue: 0
});
});
pdfParser.on("pdfParser_dataReady", pdfData => {
let data = pdfParser.getRawTextContent()
fs.writeFile('./uploads/test.txt', data, function (err) {
if (err) {
throw err;
}
});
res.status(200).json({
httpCode: 200,
message: '导入成功',
data: {
result: data
},
returnValue: 1
});
});
}
第四步:解析后删除文档
fs.unlink(excelConfig.excel_Dir, function (err) {
if (err) throw err;
console.log("删除文件" + excelConfig.excel_Dir + "成功")
})
第五步:抛出接口调用后的效果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
声明:本文内容来源于网络,版权归原作者所有,内容由互联网用户自发贡献自行上传,本网站不拥有所有权,未作人工编辑处理,也不承担相关法律责任。如果您发现有涉嫌版权的内容,欢迎发送邮件至:notice#yiidian.com(发邮件时,请将#更换为@)进行举报,并提供相关证据,一经查实,本站将立刻删除涉嫌侵权内容。
